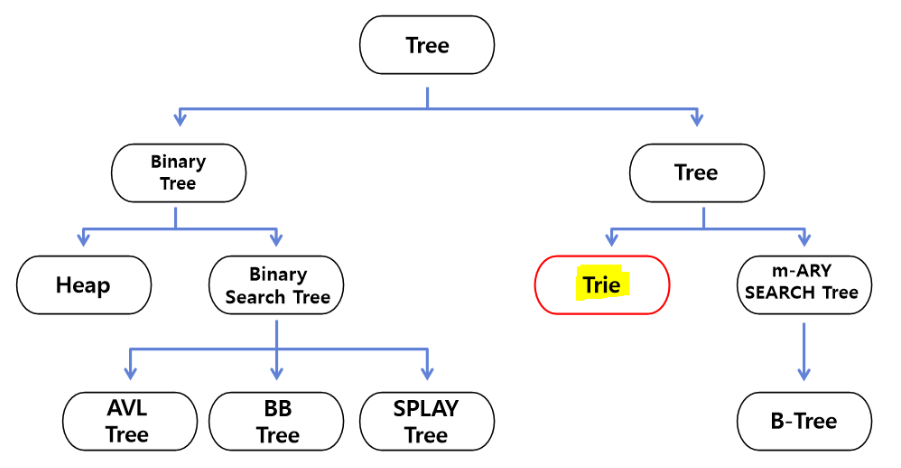
✅ 위상정렬이란? : 순서가 정해져있는 작업 을 차례대로 진행해야할 때, 그 순서를 결정해주기 위해 사용하는 알고리즘입니다. 사이클이 없는 방향 그래프(DAG)의 모든 노드를 '방향성에 거스르지 않도록 순서대로 나열하는 것'을 의미합니다. 그렇다면 순서가 있는 작업의 예시를 통해 정확하게 이해하도록 하겠습니다. 위 그래프의 흐름을 보면 '조건'으로 해석할 수 있습니다. '튀기기'전에 반드시 '닭 손질하기'를 수행해야하고, 양념에 버무리기 전에 '후라이드'와 '양념 만들기' 작업을 수행해야 합니다. 위와 같이 여러 개의 순서가 정해져있을 때, 조건에 부합하는 일직선상의 순서를 찾아보겠습니다. 위상정렬 순서: 닭 손질하기 -> 튀기기 -> 후라이드 -> 양념 만들기 -> 양념에 버무리기 -> 무많이 -> 반..