라빈 카프(Rabin-Karp) 알고리즘
라빈 카프(Rabin-Karp) 알고리즘은 특이한 문자열 매칭 알고리즘입니다. 일반적인 경우, 빠르게 작동하는 간단한 구조의 문자열 매칭 알고리즘이라는 점에서 자주 사용됩니다. 기본적으로 해시(Hash)기법을 사용하며, 해시(Hash)는 긴 데이터를 상징하는 짧은 데이터로 바꾸어주는 기법입니다. 이러한 점에서 단순 해시 알고리즘의 경우 연산 속도가 O(1)에 달한다는 장점이 있습니다.
사실 해시(Hash)만 해도 다양한 종류의 알고리즘이 있을 뿐만 아니라 각기 다르게 구현될 수 있습니다. 하지만 문자열 매칭은 '연속적인 문자열'이라는 특별한 상황에 기반하기 때문에 해시(Hash) 또한 연속적인 경우에 더 빠르게 구할 수 있는 알고리즘을 채택하여 적용한다면 빠르게 연산할 수 있습니다.
단순히 문자열을 비교하는 Naive Search의 경우, 시간 복잡도가 O(NM)이 발생합니다.(N은 전체, M은 부분) 하지만 라빈 카프(Rabin-Karp) 알고리즘을 활용하면 평균 O(N)으로 시간 복잡도를 단축시킬 수 있습니다.
abccbca의 해시값
97 * 31^6 +
98 * 31^5 +
99 * 31^4 +
99 * 31^3 +
98 * 31^2 +
99 * 31^1 +
97 * 31^0
= 87982864
쉽게 말하자면, 각 문자의 아스키코드 값에 31의 제곱 수를 차례대로 곱하여 더해준 것입니다. 이러한 방식을 사용한다면 서로 다른 문자열의 경우, 일반적으로 다른 해시값이 나오게 됩니다. 또한, 31의 제곱 수를 곱하는 과정에서 오버플로우가 발생할 수 있기 때문에 MOD를 활용했습니다 (이때 MOD는 1억7)
물론 해시 값이 중복되는 충돌(Collision)현상이 발생할 수 있습니다. 실제로는 이를 대비하기 위해 List를 활용한 연결된 자료구조를 이용합니다. (해당 사항은 다음 포스팅에서 다루겠습니다.)
즉, 라빈 카프 알고리즘은 여러 개의 문자열을 비교할 때, 항상 해시 값을 구하여 비교하고, '긴 문자열'과 '부분 문자열'의 해시값이 일치하는 경우에만 문자열을 재검사하여 정확히 일치하는지 확인하는 알고리즘입니다.
그렇다면 어떻게 라빈 카프 알고리즘의 시간복잡도가 평균 O(N)인지 확인해보겠습니다.
| a | b | c | c | b | c | a |
위처럼 abccbca의 문자열 중 abc의 해시값은 96354이 나옵니다. 여기서 만약 한 칸 이동한 결과는 어떻게 빠르게 구할 수 있는지 알아봅시다.
| a | b | c | c | b | c | a |
바로 가장 앞에있는 문자 'a'만큼의 수치를 뺀 뒤, 거듭제곱 수인 31을 곱하고 새롭게 뒤에 들어온 'c'의 수치를 더해주는 것입니다.
긴 문자열 해시값 = 31 * (긴 문자열 해시값 - 가장 앞에 있는 문자의 수치값) + 새롭게 들어온 문자의 수치값
이러한 공식을 사용하면 앞에서부터 뒤로 쭉 읽으면서 값을 구할 수 있기 때문에 시간 복잡도는 평균 O(N)이 나오게 되는 것입니다.
<실제 코드>
import java.util.*;
import java.io.*;
public class RabinKarp {
public static void main(String[] args) throws IOException {
String parent = "ababacabacaabacaaba";
String pattern = "abacaaba";
findStringPattern(parent, pattern);
}
public static void findStringPattern(String parent, String pattern) {
final int MOD = 100000007;
int parentSize = parent.length();
int patternSize = pattern.length();
long parentHash = 0, patternHash = 0, power = 1;
for(int i=0; i<=parentSize-patternSize; i++) {
if(i == 0) {
for(int j=0; j<patternSize; j++) {
parentHash = (parentHash + (parent.charAt(patternSize-1-j)) * power) % MOD;
patternHash = (patternHash + (pattern.charAt(patternSize-1-j)) * power) % MOD;
if(j < patternSize-1) {
power = (power%MOD * 31) % MOD;
}
}
} else {
parentHash = 31*parentHash%MOD - 31*parent.charAt(i-1)*power%MOD + parent.charAt(i+patternSize-1);
parentHash %= MOD;
}
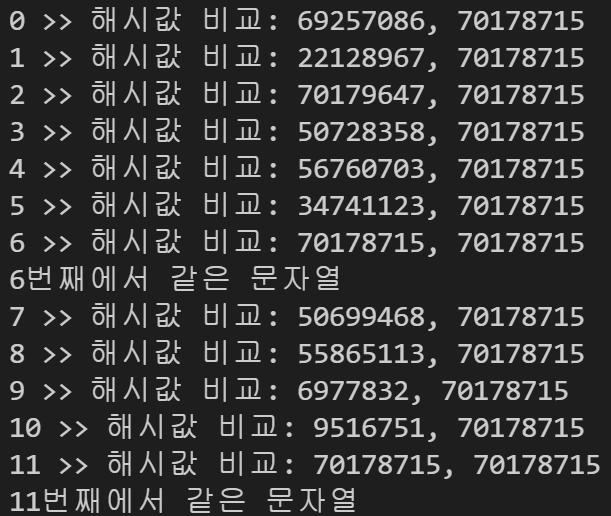
System.out.println(i+" >> 해시값 비교: "+parentHash+", "+patternHash);
if(parentHash == patternHash) {
System.out.println(i+"번째에서 같은 문자열");
}
}
}
}
위처럼 int형 대신 long형과 나머지 연산(MOD)을 통해 안정적인 프로그래밍을 진행하였습니다. 물론 MOD없이 진행하여도 동일한 간격으로 음수와 양수를 왔다갔다하므로 해시 값 자체는 동일합니다.
'Developer's_til > 자료구조 & 알고리즘' 카테고리의 다른 글
| [자료구조] Trie(트라이)에 대한 개념과 활용법 (0) | 2021.07.15 |
|---|---|
| [문자열 탐색] KMP(Knuth-Morris-Pratt) 알고리즘 (0) | 2021.06.10 |
| [문자열 탐색] Naive 알고리즘과 Hashing 기법 (0) | 2021.06.04 |
| [동적계획법] Top-down과 Bottom-up (1) | 2021.03.31 |
| [자료구조] Union-find (1) | 2021.03.29 |