이전 포스팅에서는 머신러닝의 비지도학습 중 대표적인 Clustering을 다뤄봤습니다. 이번에는 머신러닝의 지도학습에 해당하는 KNN 알고리즘에 대해 알아보겠습니다.
KNN 알고리즘은 최근접 이웃 알고리즘이라고도 합니다. 새로운 데이터를 입력받았을 때, 이 데이터와 가장 근접한 데이터들의 종류가 무엇인지 확인하고 해당 그룹으로 분류하는 알고리즘입니다.
KNN은 아래처럼 3단계에 걸쳐 진행됩니다.
1. 주변 데이터 간의 거리계산하기
2. 가장 근처에 있는 요소 뽑기
3. 분류되는 군집 예측하기
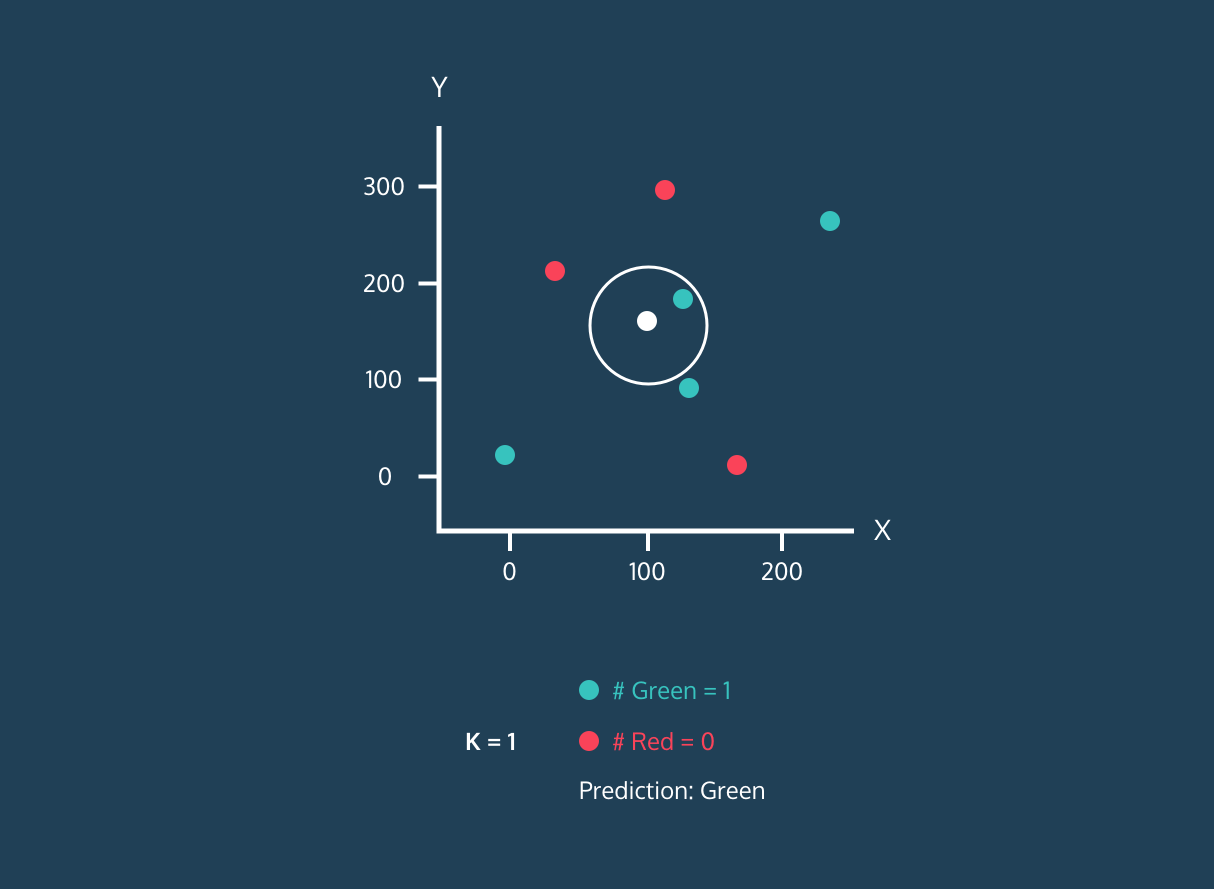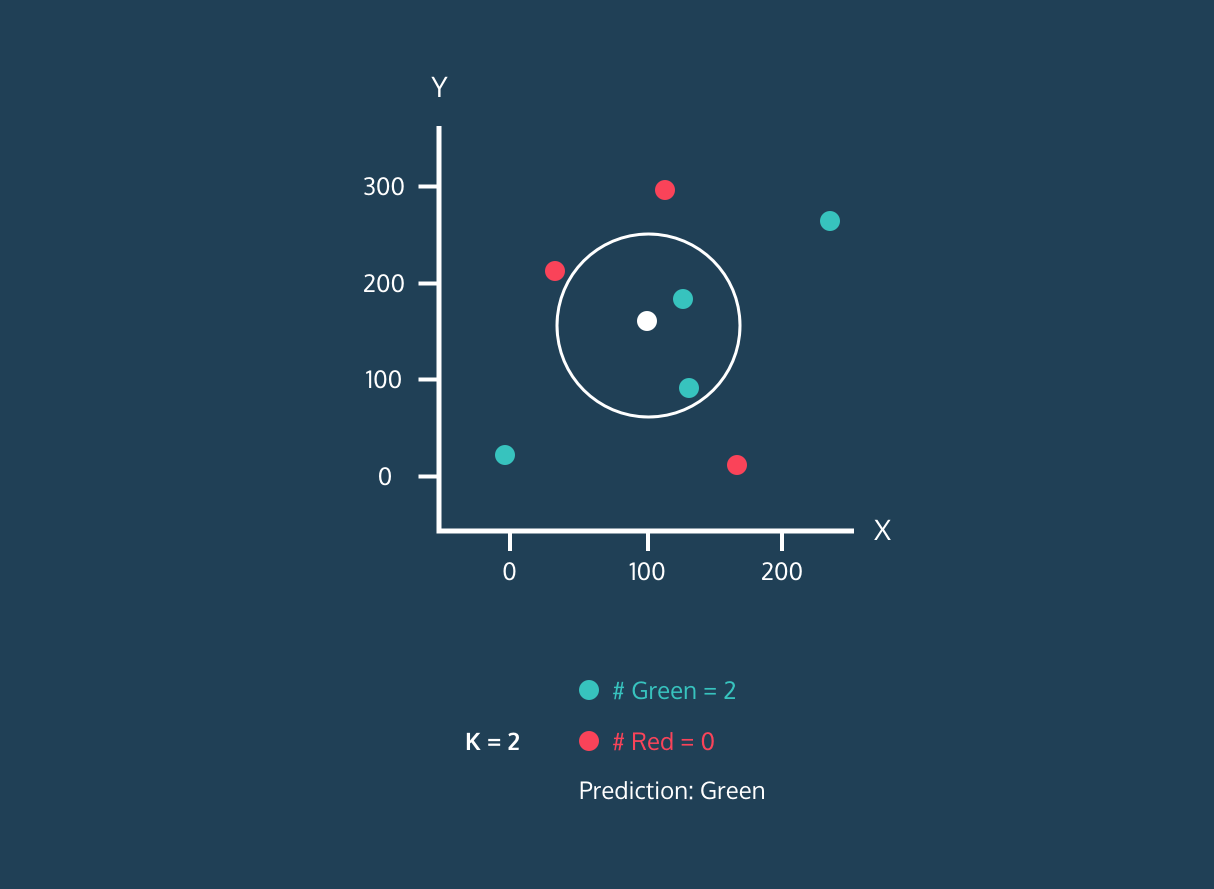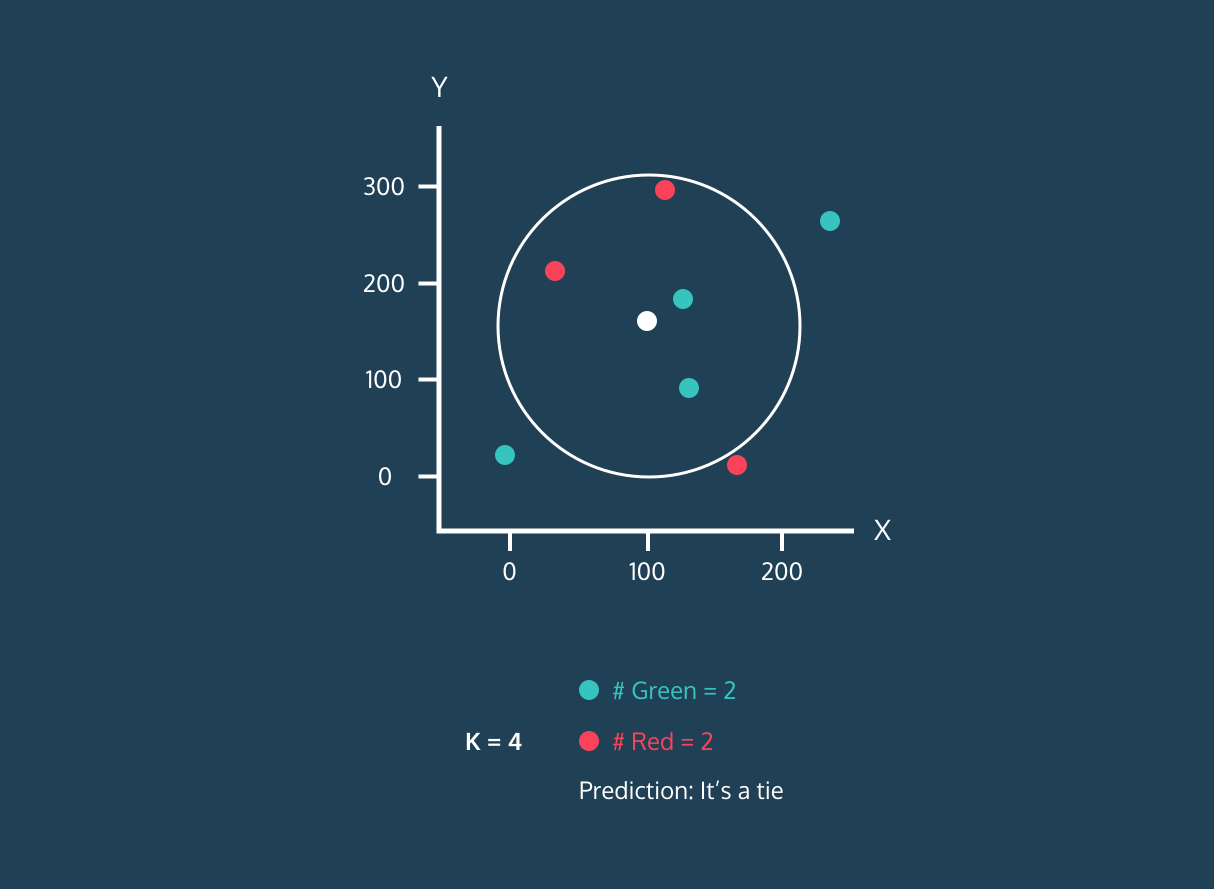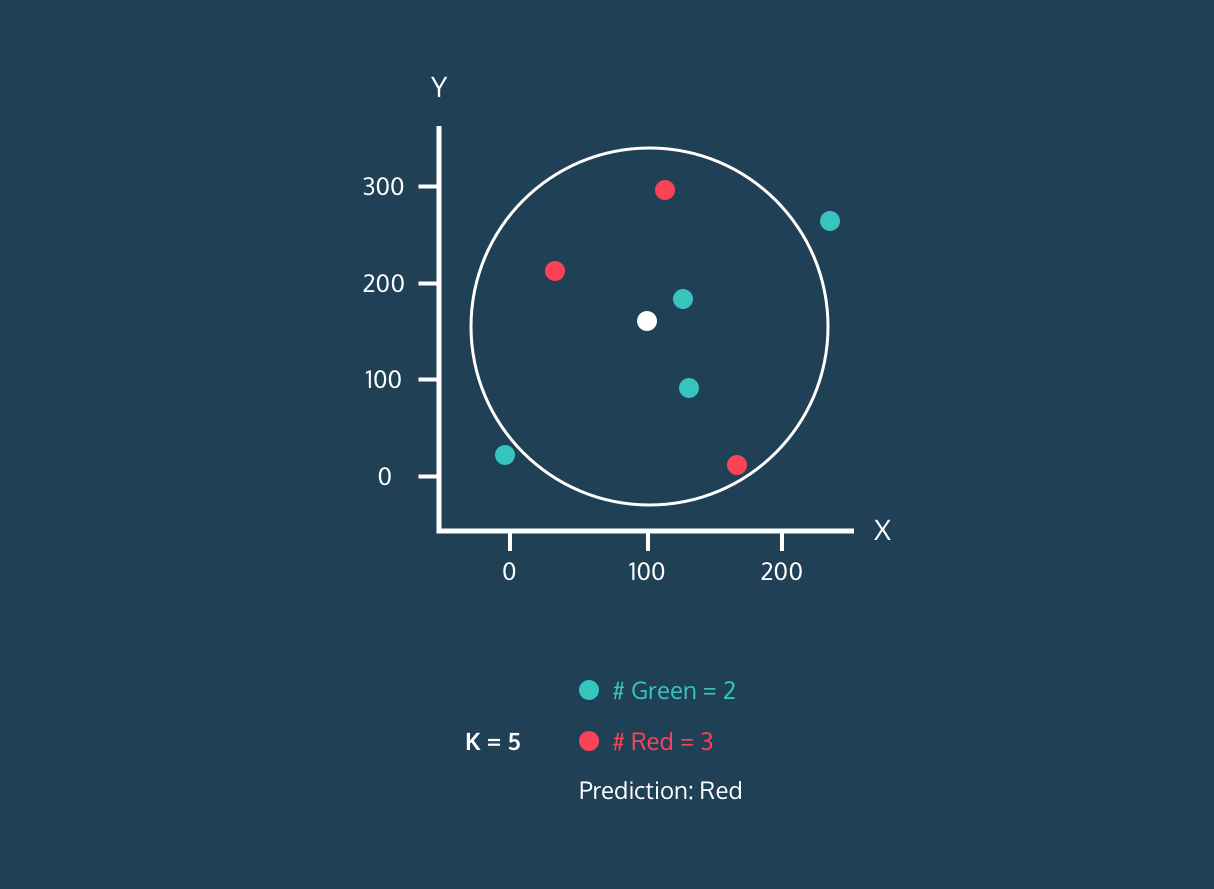
위 그림은 KNN알고리즘의 동작 과정으로 신규 데이터(흰색)가 K값에 따라 분류되는 군집을 Prediction으로 확인할 수 있습니다. 다만, K를 너무 작게 설정하면 과적합이 우려되며 너무 크게 설정하면 데이터 구조 파악이 어렵습니다.
Python으로 직접 구현한 KNN
영화 데이터를 활용해 새로 등록되는 데이터가 어느 군집에 속하는지 분류해주는 KNN을 구현해보겠습니다. 영화 데이터는 이전 포스팅에서 활용한 장르와 영화 테이블을 사용하겠습니다.

class Movie(models.Model):
id = models.IntegerField(primary_key=True)
title = models.CharField(max_length=200)
genres = models.CharField(max_length=500)
watch_count = models.IntegerField(default=0)
averagerate = models.IntegerField(default=0)
plot = models.CharField(default='', max_length=1000)
url = models.CharField(default='', max_length=500)
director = models.CharField(default='', max_length=500)
casting = models.CharField(default='', max_length=500)
score_users = models.ManyToManyField(Profile, through='Rate', related_name='score_movies')
@property
def genres_array(self):
return self.genres.strip().split('|')
def __str__(self):
return self.title
신규 데이터와 기존 데이터의 거리는 장르와 장르를 제외한 다른 데이터와의 유사성을 기준으로 결정하겠습니다.
1. 주변 데이터 간의 거리 계산하기
label = ["Action","Adventure","Animation","Children's",
"Comedy","Crime","Documentary","Drama","Fantasy",
"Film-Noir","Horror","Musical","Mystery","Romance",
"Sci-Fi","Thriller","War","Western"]
newMovie(request)
newMovie_genre = [0 for i in range(len(label))]
# 신규 영화의 장르배열
for genre in newMovie.genres.split("|"):
idx = label.index(genre)
newMovie_genre[idx] = 1먼저, 신규 데이터 생성과 동시에 장르 배열을 만들어줍니다. 전체 영화의 pk를 배열 idx로 갖는 dist_movie를 생성해 데이터 간의 거리를 저장해줍니다.
import numpy as np
# 영화간의 거리 계산(장르, 감독, 배우)
def distance_movie(inputMovie, inputMovie_genre, movie_genre, movie_pk):
movie = Movie.objects.get(pk=movie_pk)
dist = np.linalg.norm(inputMovie_genre - movie_genre)
for cast in movie.casting.split("|"):
if cast in inputMovie.casting.split("|"):
dist -= 0.1
if movie.director == inputMovie.director:
dist -= 0.1
return dist
# 데이터 간의 거리배열
dist_movie = [0 for i in range(movies_pk.values[-1]+1)]
inputMovie_genre = np.array(inputMovie_genre)
for movie_genre, movie_pk in zip(Movies.values, movies_pk):
temp = distance_movie(inputMovie, inputMovie_genre, movie_genre, movie_pk)
dist_movie[movie_pk] = temp # 거리 저장.장르 배열의 유클리드 거리를 numpy의 linalg.norm() 함수로 처리했습니다. 그리고 영화감독과 배우 중 동일인물이 있을 때마다 0.1만큼 가깝다고 판단하며 데이터 간의 거리를 계산했습니다.
2. 가장 근처에 있는 요소 뽑기
이제 신규 데이터와 가장 가까운 데이터 7개를 뽑아 어떤 군집에 가장 많이 분류되었는지 확인합니다.
# 가장 가까운 영화 출력
def findnearMovie(movie):
nearMovie = min(movie)
idx = movie.index(nearMovie)
return idx
# 가장 가까운 영화 7개
Nearest_movie = []
dist_movie.sort()
for i in range(7):
Nearest_movie.append(dist_movie[i])
3. 분류되는 군집 예측하기
마지막으로 가장 가까운 영화 7개 중 분류되는 군집을 예측합니다.
from sklearn.cluster import KMeans
import pandas as pd
K = 3
df = pd.DataFrame(movies)
model = KMeans(n_clusters=K, algorithm='auto').fit(df)
predict = model.labels_
# DB에 저장하기 위한 array 생성
predictList = [0 for i in range(K+1)]
for pk in Nearest_data:
predictList[predict[pk-1]] += 1
prediction = predictList.index(max(predictList))기존에는 영화 데이터의 K-Means Clustering의 결과를 DB에 저장했으나 여기서는 없다고 가정.
sklearn라이브러리를 활용해 Kmeans의 결과를 model에 저장했습니다. Nearest_data에는 앞에서 구한 신규 데이터와 가장 가까운 데이터의 pk가 담겨 있습니다.
for문을 통해 predict[pk-1]은 군집 결과(0~2)가 담겨있으므로 이를 predictList에 저장합니다. (예를 들어 pk=1이 군집 2에 속해있다면 predictList[2]에 1을 추가)
위 과정을 거치면 predictList의 max값의 index가 신규 데이터가 분류되는 군집인 prediction을 예측할 수 있습니다.
지금까지 KNN 알고리즘에 대해 알아보았습니다. 이 포스팅은 영화 추천 엔진을 제작하면서 적용했던 코드로 영화뿐만 아니라 유저에 대해서도 KNN알고리즘을 적용했습니다. 실제로 마지막 예측 단계에서는 군집 수(K)를 3~7로 설정해서 반복문을 돌리고 예측 결과를 DB에 저장해 관리했습니다.
'Developer's_til > 그외 개발 공부' 카테고리의 다른 글
| [객체지향] Java를 Java스럽게 (1) | 2020.10.28 |
|---|---|
| 컴파일러와 인터프리터의 차이? (1) | 2020.10.28 |
| Python을 활용한 K-means Clustering (0) | 2020.10.04 |
| [Java] Scanner와 BufferedReader, 뭘로 입력할까? (1) | 2020.10.01 |
| String, StringBuilder, StringBuffer의 차이? (0) | 2020.10.01 |