클러스터링은 비지도 학습기법으로 유사한 유형의 데이터를 그룹화함으로써 숨겨진 구조를 파악합니다.
클러스터링을 활용하면 추천 엔진, 검색 엔진, 시장 세분화 등을 구현할 수 있습니다.
K-means Clustering이란?
"K"는 주어진 데이터를 그룹화할 수 즉, 클러스터 개수를 말합니다. "Means"는 각 클러스터의 중심과 데이터들의 평균 거리를 의미합니다. 이 때, 클러스터의 중심을 centroids라고 합니다.
K-means 알고리즘은 다음과 같은 과정을 수행합니다.
1. 데이터셋에서 K개의 centroids를 임의로 지정.
2. 각 데이터들을 가장 가까운 centroids와 같은 그룹으로 할당.
3. 2번 과정에서 할당된 결과로 centroids를 다시 지정.
4. 2~3번 과정을 반복하면서 centroids가 더 이상 변하지 않을 때까지 반복.
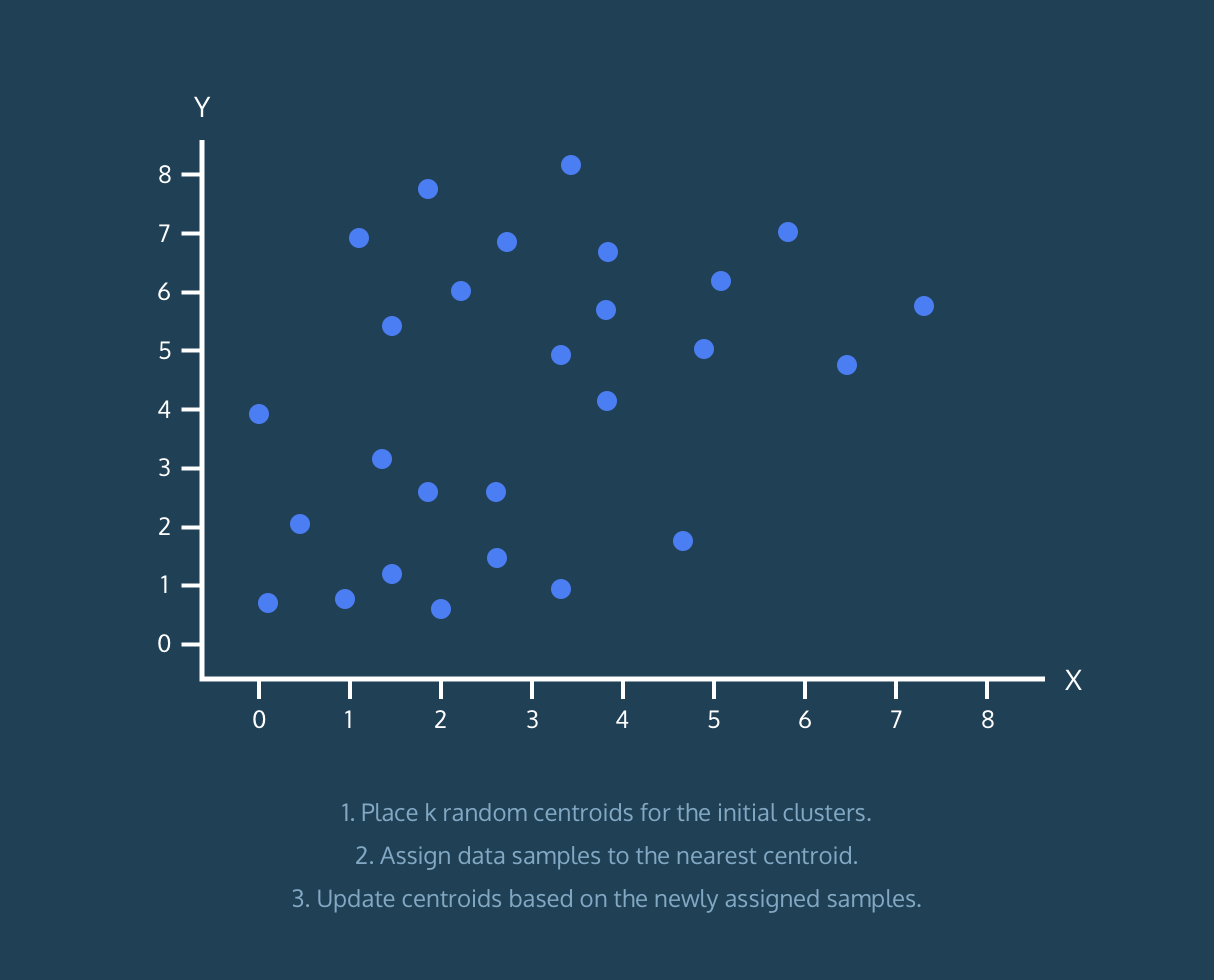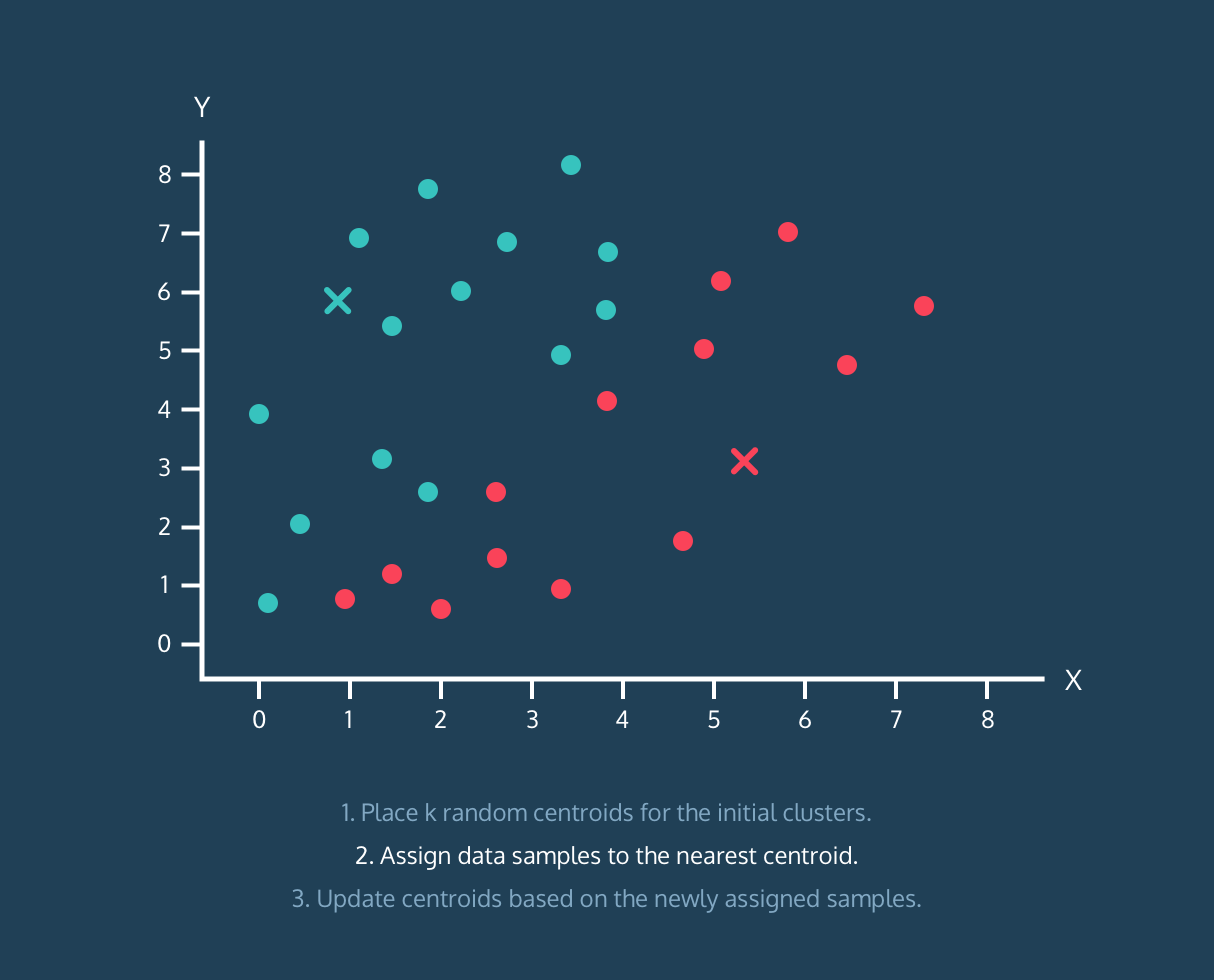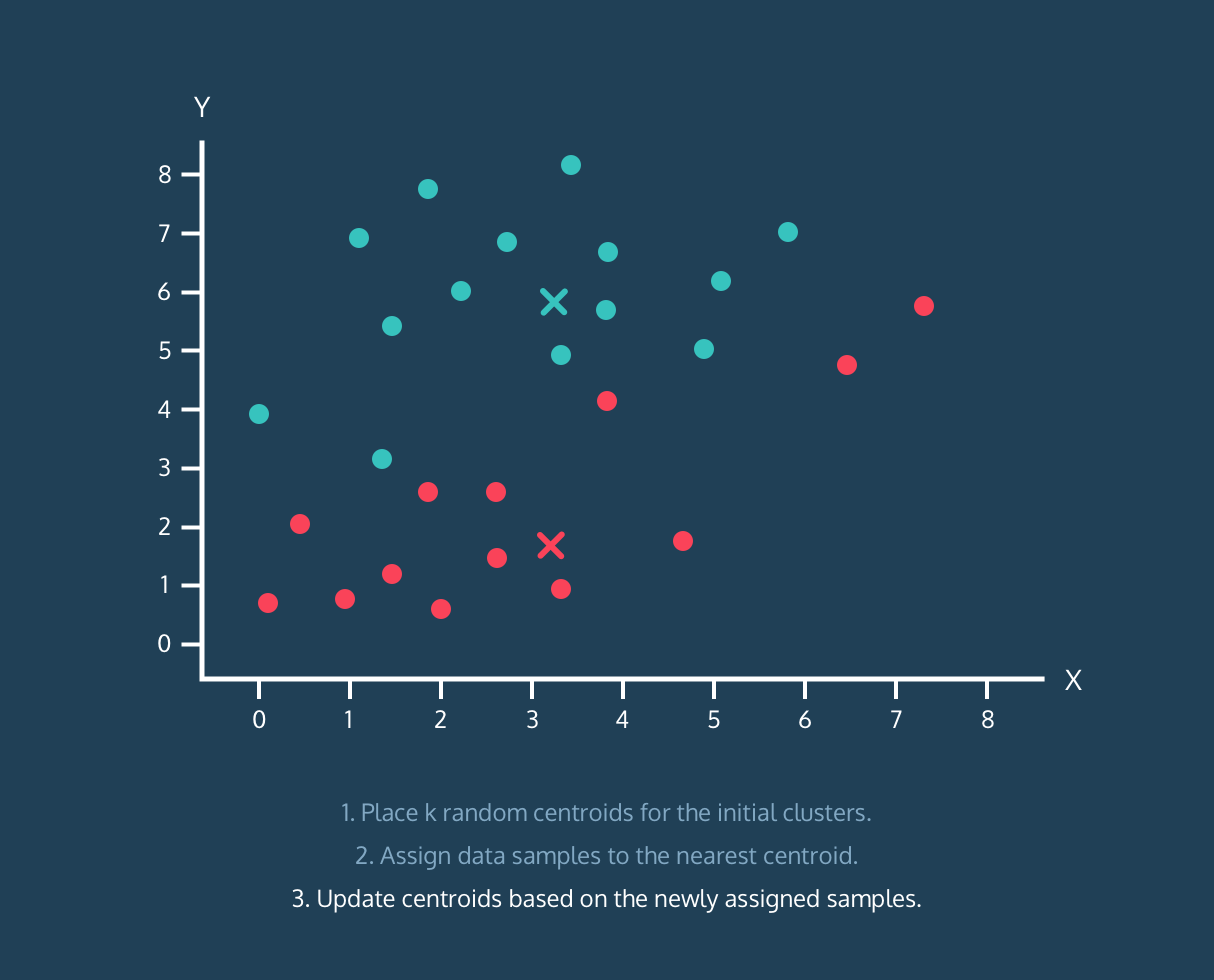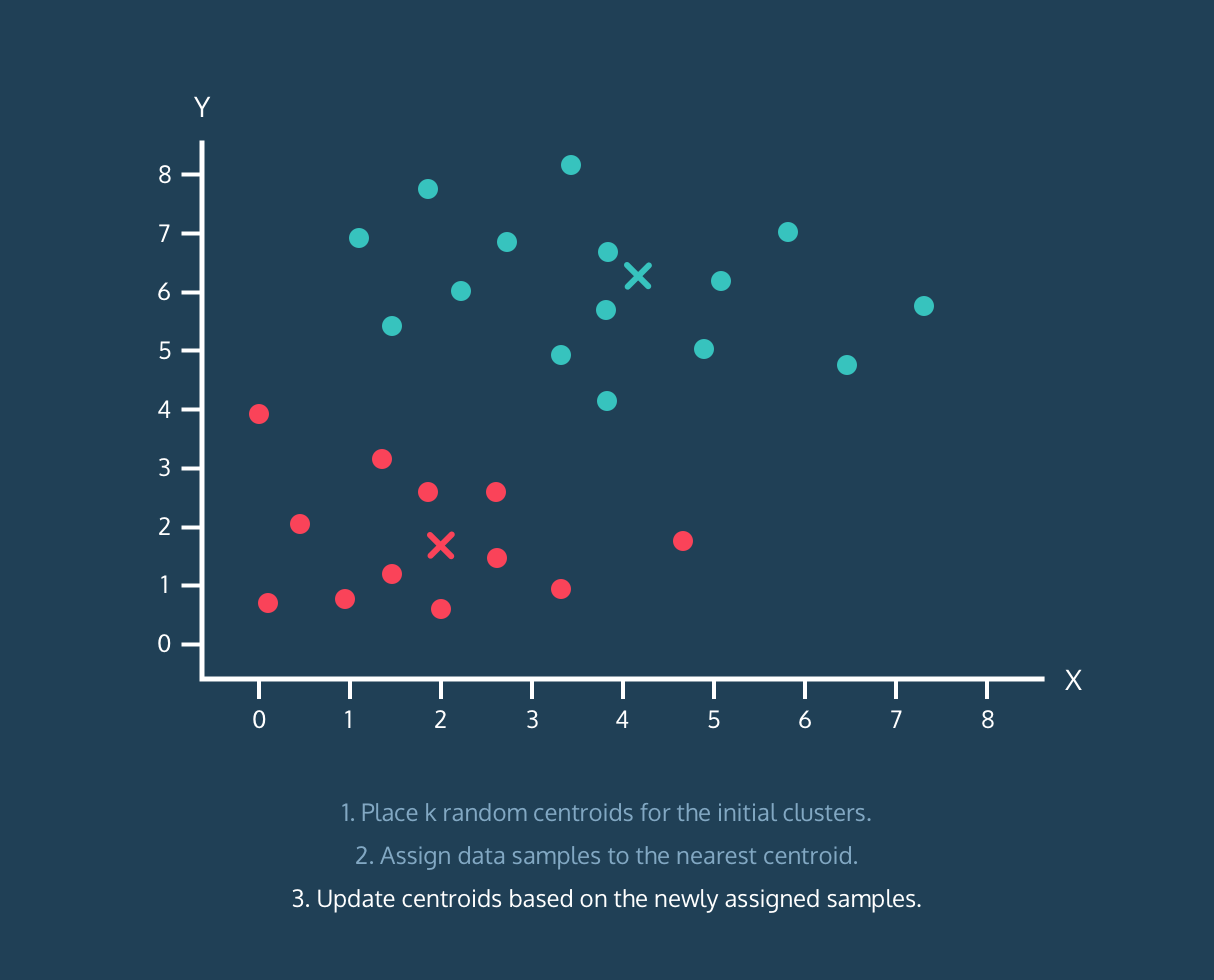
위와 같은 과정을 통해 데이터의 군집화가 이뤄집니다. 이번에는 Python으로 직접 알고리즘을 구현한 후, sklearn을 활용해 구현해보겠습니다. (프로젝트에서 진행했던 영화 장르 데이터를 기준으로 했습니다.)
직접 구현하는 K-Means Clustering
1. Centroids 지정하기
영화의 장르만을 기준으로 군집을 형성해주기 위해 장르 도메인과 영화명을 컬럼으로 잡았습니다. 이제 numpy를 활용한 centroids를 임의로 지정합니다.
import numpy as np
k = 3
# 랜덤으로 x, y 좌표 3개를 생성합니다
# np.random.uniform은 주어진 최소, 최대값 사이에서 k 개 만큼 실수 난수를 생성합니다.
centroids = np.random.uniform(1, maxMovieCnt, k)
2. 데이터들을 가장 가까운 centroid로 할당하기
각 데이터를 벡터로 간주하여 유클리드 거리를 계산해 가까운지를 판단합니다.
# 영화별 모든 장르 고려
def distance(centroid_movie, movie):
return sum([(genre1 - genre2)**2 for genre1, genre2 in list(zip(centroid_movie, movie))]) ** 0.5이제 각 데이터들 별로 3개의 centroids와의 거리를 측정합니다. 이때 labels이란 배열을 생성해, 가장 가까운 centrodis의 index를 저장합니다.
# 각 데이터 포인트를 그룹화 할 labels을 생성합니다 (0, 1, 또는 2)
labels = np.zeros(len(movies))
# 각 데이터를 순회하면서 centroids와의 거리를 측정합니다
for i in range(len(movies)):
distances = np.zeros(k) # 초기 거리는 모두 0으로 초기화 해줍니다
for j in range(k):
distances[j] = distance(centroids[j][0:17], movies[i][0:17])
cluster = np.argmin(distances) # np.argmin은 가장 작은 값의 index를 반환합니다
labels[i] = cluster
이렇게 생성한 labels에는 0~2가 저장되어 각 데이터가 어느 centroid에 속하는지 나타나게 됩니다.
3. Update Centroids
이제 centroids를 새로 지정해서 데이터의 그룹화를 개선시킵니다. 기존에 지정한 centroids를 deep copy를 활용해centroids_old에 저장합니다.
from copy import deepcopy
centroids_old = deepcopy(centroids)2번 결과에서 각 군집별로 centrorids를 다시 계산합니다.
for i in range(k):
# 각 그룹에 속한 데이터들만 골라 points에 저장합니다
points = [movies[j][0:17] for j in range(len(movies)) if labels[j] == i]
# points의 각 feature, 즉 각 좌표의 평균 지점을 centroid로 지정합니다
centroids[i] = np.mean(points, axis=0)
4. Repeat step 2~3 until Convergence
이제 앞서 말한 것처럼 centroids가 더 이상 변하지 않을 때까지 반복합니다. 이를 error라는 배열을 생성해 centroids_old와 새롭게 지정된 centroids의 거리를 저장합니다. 만약, 이 거리가 모두 0이되면 최적해에 수렴한 것으로 판단하고 반복을 종료합니다.
# 제일 처음 centroids_old는 0으로 초기화 해줍니다.
centroids_old = np.zeros(centroids.shape)
labels = np.zeros(len(movies))
# error 도 초기화 해줍니다
error = np.zeros(k)
for i in range(k):
error[i] = distance(centroids_old[i], centroids[i])
# STEP 4: error가 0에 수렴할 때 까지 2 ~ 3 단계를 반복합니다
while(error.all() != 0):
for i in range(len(movies)):
distances = np.zeros(k)
for j in range(k):
distances[j] = distance(centroids[j][0:17], movies[j][0:17])
cluster = np.argmin(distances)
labels[i] = cluster
centroids_old = deepcopy(centroids)
for i in range(k):
points = [ movies[j][0:17] for j in range(len(movies)) if labels[j] == i ]
centroids[i] = np.mean(points, axis=0)
# 새롭게 centroids를 업데이트 했으니 error를 다시 계산합니다
for i in range(k):
error[i] = centroids_old[i] - centroids[i]
Scikit-Learn으로 구현하는 K-Means Clustering
앞에서는 직접 알고리즘을 구현하느라 코드 양이 상당히 많고 복잡했습니다. 하지만 scikit-learn 라이브러리를 활용하면 간편하게 구현할 수 있습니다.
from sklearn.cluster import KMeans
k = 3
model = KMeans(n_cluster=k)
# K-Means 클러스터링 수행
model.fit(movies)
# K-Means 수행 후, 데이터를 군집에 할당
labels = model.predict(movies)실제 프로젝트에선 아래와 같은 방법을 사용했습니다.
from sklearn.cluster import KMeans
# group = pd.read_csv("./api/fixtures/user_clu.csv", header=0)
# group = group[["Action","Adventure","Animation","Children's",
# "Comedy","Crime","Documentary","Drama","Fantasy",
# "Film-Noir","Horror","Musical","Mystery","Romance",
# "Sci-Fi","Thriller","War","Western"]]
group.head()
model1 = kmeans(3, group)
users_Kmeans = model1.train_cluster()[1]
여기까지 K-Means Clustering 알고리즘에 대한 포스팅을 마치겠습니다. 이외에도 Hierarchical Clustering, EM Clustering, Number of Clusters가 있으나 나중에 다뤄보도록 하겠습니다.
'Developer's_til > 그외 개발 공부' 카테고리의 다른 글
| [객체지향] Java를 Java스럽게 (1) | 2020.10.28 |
|---|---|
| 컴파일러와 인터프리터의 차이? (1) | 2020.10.28 |
| Python을 활용한 KNN 알고리즘 (1) | 2020.10.04 |
| [Java] Scanner와 BufferedReader, 뭘로 입력할까? (1) | 2020.10.01 |
| String, StringBuilder, StringBuffer의 차이? (0) | 2020.10.01 |