크롤링이란?
간단히 말하자면, 인터넷에 있는 정보들을 자동으로 수집하는 행위를 말합니다.
지난 9월에 데이터 수집 업무를 맡았었습니다. 예전 같았으면 인터넷에서 하나씩 검색해서 엑셀에 저장했을텐데 나름 개발자라고 크롤링하면서 편하게 업무 처리했네요. 그래서 실제로 제가 어떻게 크롤링을 업무에 활용했는지 소개해드리고자 합니다.
가장 먼저 Python과 IDE설치 및 pip를 설치해서 개발 환경을 구축했습니다. 이 부분은 직접 구글링하시는 걸 추천드립니다.
1. ChromeDriver와 Selenium
크롤링에 사용할 프레임워크는 Selenium의 webDriver입니다. webDriver를 활용하면 Python으로 가상 브라우저(Chrome)를 실행해 자유롭게 검색할 수 있는 환경이 만들어집니다.
But 여기서 끝이아니라 Chrome브라우저를 이용하려면 ChromeDriver를 설치해야 합니다. ChromeDriver는 webDriver로 명령을 보낼때 Chrome을 제어하는 방법을 제공해줍니다.
chromedriver.chromium.org/downloads
Downloads - ChromeDriver - WebDriver for Chrome
WebDriver for Chrome
chromedriver.chromium.org
개발환경 구축 및 ChromeDriver를 설치하셨다면 Selenium이란 오픈소스를 cmd창 또는 IDE의 터미널에서 설치하겠습니다.
pip install selenium
여기까지 완료되셨다면 다음 코드를 사용해 가상 브라우저를 실행해보겠습니다.
from selenium import webdriver
# 실행한 웹 사이트
URL = "https://www.naver.com/"
# chromedriver.exe의 위치
driver_path = r'C:\Users\82103\Desktop\크롤링\chromedriver_win32\chromedriver.exe'
driver = webdriver.Chrome(driver_path)
driver.get(URL)

가상 브라우저가 실행되셨다면 크롤링을 위한 준비과정이 끝났습니다.
2. Selenium의 메소드 활용하기
이제 임의의 정보를 검색해서 원하는 데이터를 가져와야합니다. 이를 위해 webDriver는 브라우저의 HTML tag, class, name 등에 접근할 수 있는 메소드를 제공합니다. 참고로 브라우저의 HTML은 ctrl + shift + I 또는 마우스 우클릭해서 검사를 눌러서 확인할 수 있습니다.
- driver.find_element_by_name()
- driver.find_element_by_tag_name()
- driver.find_element_by_class_name()
- driver.find_element_by_id()
- driver.find_element_by_xpath()
- driver.find_element_by_css_selector()
| 메소드 | 설명 |
| driver.find_element_by_name().send_keys() | 입력 form에 문자열 입력하기 |
| driver.find_element_by_name().click() | 해당 요소 마우스 클릭하기 |
| driver.find_element_by_name().text | 해당 요소의 문자열(text)를 가져오기 |
| driver.find_element_by_name().clear() | 해당 요소의 입력 form을 초기화하기 |
| driver.get() | 브라우저 실행 |
| driver.back() | 뒤로 가기 |
| driver.close() | 브라우저 종료 |
| driver.getTitle() | 브라우저 제목 가져오기 |
이제 위에 있는 메소드를 활용해 3단계를 거쳐 데이터를 수집해보겠습니다.
1. 네이버 실행
2. 정보 검색
3. 결과값 가져오기
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
URL = "https://www.naver.com/"
driver_path = r'C:\Users\82103\Desktop\크롤링\chromedriver_win32\chromedriver.exe'
driver = webdriver.Chrome(driver_path)
driver.get(URL)
driver.find_element_by_id('query').send_keys('BTS')
driver.find_element_by_id('search_btn').click()
time.sleep(1)
name = driver.find_element_by_class_name('name').text
print(name)
이를 실행하면 name에는 '방탄소년단 (BTS) 가수'라는 값이 저장되어 출력됩니다.
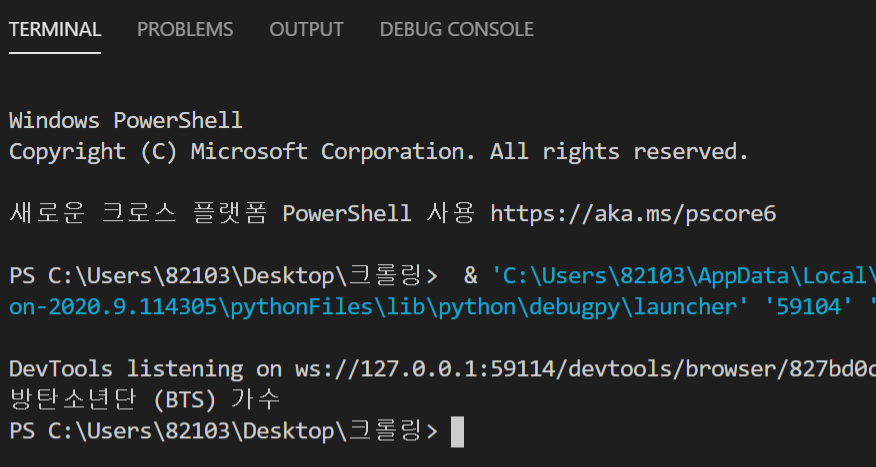
그렇다면 다음과 같이 2개 이상의 tag에서 특정 tag에만 접근해 데이터를 수집하는 방법을 보여드리겠습니다.

우측 HTML을 보면 <dd>태그와 <dt>태그가 2개 이상있습니다. 여기서 두번째 <dd>태그에 접근해 멤버들의 이름을 가져오겠습니다.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
import time
URL = "https://www.naver.com/"
driver_path = r'C:\Users\82103\Desktop\크롤링\chromedriver_win32\chromedriver.exe'
driver = webdriver.Chrome(driver_path)
driver.get(URL)
driver.find_element_by_id('query').send_keys('BTS')
driver.find_element_by_id('search_btn').click()
time.sleep(1)
member = driver.find_element_by_class_name('detail_profile')
member = member.find_elements_by_tag_name('dd')[1]
member = member.find_elements_by_tag_name('a')
for name in member:
print(name.text)
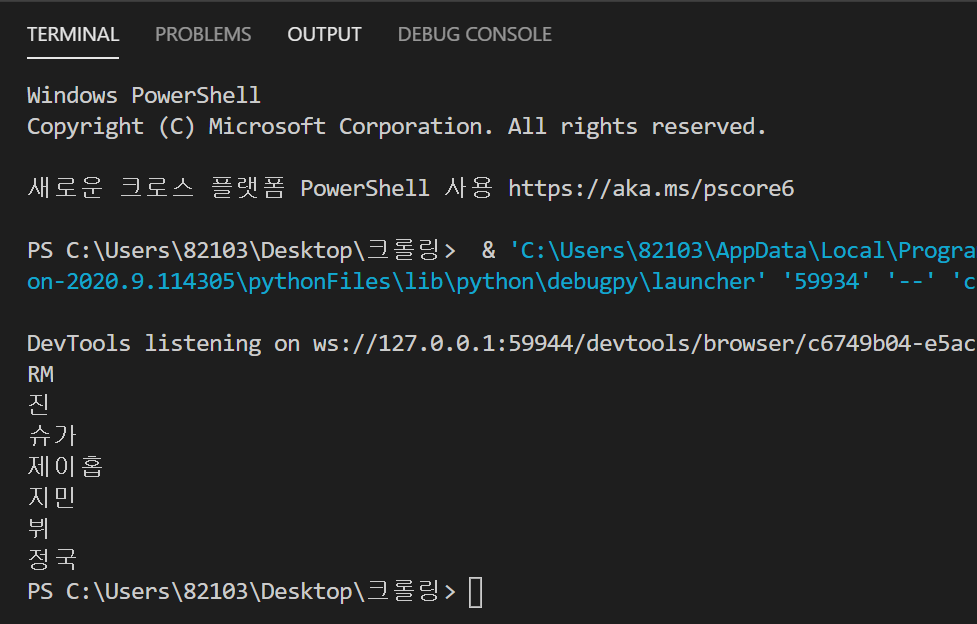
앞 코드와는 다르게 member변수에 HTML경로를 저장했습니다. 이런 식으로 경로를 저장해 추가 작업이 가능합니다. 또한, element대신 elements를 사용해 2개 이상의 경로를 배열 형태로 member변수에 저장했습니다. 배열 index는 0부터 시작하므로 두번째 <dd>태그에 접근하기위해 1번째 index에 접근했습니다.
마지막으로 멤버들의 이름이 저장된 모든 <a>태그를 member변수에 저장해서 출력해줬습니다. 결과값은 다음과 같이 나옵니다.
이외에도 find_element_by_xpath를 활용해 절대경로와 상대경로로 HTML태그에 접근할 수 있습니다. 실제로 활용해봤는데 xpath의 문법을 익히고 표현법에 따라 사용해야돼서 생각보다 복잡했습니다. 오히려 직관적으로 tag와 name, class를 이용한게 훨씬 빠르고 쉽게 개발할 수 있었습니다.
이상으로 동적 웹 크롤링 기법에 대한 포스팅을 마치겠습니다.
'Developer's_til > 그외 개발 공부' 카테고리의 다른 글
| [Java] JDK8부터 등장한 Stream API (0) | 2021.07.29 |
|---|---|
| 객체지향 프로그래밍(OOP)의 설계 원칙 'SOLID' (0) | 2021.04.27 |
| [Clean Code] 네이밍 기법, 카멜과 파스칼, 스네이크? (0) | 2020.10.28 |
| [객체지향] Java를 Java스럽게 (1) | 2020.10.28 |
| 컴파일러와 인터프리터의 차이? (0) | 2020.10.28 |